Protecting Your Users' Data with a Privacy Wall

The Privacy Wall
The idea is simple: don't have any direct links in your database between your users' "public" data and their private data. Instead of linking tables directly via a foreign key, use a cryptographic hash [1] that is based on at least one piece of data that only the user knows—such as their password. The user's private data can be looked up when the user logs in, but otherwise it is completely anonymous. Let's go through a simple example.
Let's say we're designing an application that lets members keep a list of their deepest, darkest secrets. We need a database with at least two tables: 'users' and 'secrets'. The first pass database model looks like this:
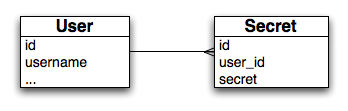
The problem with this schema is that anyone with access to the database can easily find out all the secrets of a given user. With one small change, however, we can make this extremely difficult, if not impossible:
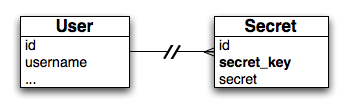
The special sauce is the 'secret_key', which is nothing more than a cryptographic hash of the user's username and their password [2]. When the user logs in, we can generate the hash and store it in the session [3]. Whenever we need to query the user's secrets, we use that key to look them up instead of the user id. Now, if some baddie gets ahold of the database, they will still be able to read everyone's secrets, but they won't know which secret belongs to which user, and there's no way to look up the secrets of a given user.
Update: A commenter on the Wesabe blog brought up the important point of what you do if the user forgets their password. The recovery method we came up with was to store a copy of their secret key, encrypted with the answers to their security questions (which aren't stored anywhere in our database, of course). Assuming that the user hasn't forgotten those as well, you can easily find their account data and "move it over" when they reset their password (don't forget to update the encrypted secret key); if they do forget them, well, there's a problem.
Attacking the Wall
I mentioned earlier that you store the secret key in the user's session. If you're storing your session data in the database and your db is hacked, any users that are logged in (or whose sessions haven't yet be deleted) can be compromised. The same is true if sessions are stored on the filesystem. Keeping session data in memory is better, although it is still hackable (the swapfile is one obvious target). However you're storing your session data, keeping your sessions reasonably short and deleting them when they expire is wise. You could also store the secret key separately in a cookie on the user's computer, although then you'd better make damn sure you don't have any cross-site scripting (XSS) vulnerabilities that would allow a hacker to harvest your user's cookies.
Other holes can be found if your system is sufficiently complex and an attacker can find a path from User to Secret through other tables in the database, so it's important to trace out those paths and make sure that the secret key is used somewhere in each chain.
A harder problem to solve is when the secrets themselves may contain enough information to identify the user, and with the above scheme, if one secret is traced back to a user, all of that user's secrets are compromised. It might not be possible or practical to scrub or encrypt the data, but you can limit the damage of a secret being compromised. My colleague and security guru Sam Quiqley suggests the following as an extra layer of security: add a counter to the data being hashed to generate the secret key:
secret key 1 = Hash(salt + password + '1')
secret key 2 = Hash(salt + password + '2')
...
secret key n = Hash(salt + password + '<n>')Getting a list of all the secrets for a given user when they log in is going to be a lot less efficient, of course; you have to keep generating hashes and doing queries until no secret with that hash is found, and deleting secrets may require special handling. But it may be a small price to pay for the extra privacy.
Finally, log files can be a gold mine for attackers. There's a very good chance you're logging queries, debug statements, or exception reports that link users to their keys or directly to their secrets. You should scrub any identifying information before it gets written to the log file.
So That's It, Right?
The privacy wall is far from a silver bullet. Privacy and security are hard—really hard—particularly so if your app is taking private data and extracting information out of it for public consumption, like we are at Wesabe. The privacy wall is one of a number of methods we're using to insure that our users' private data stays that way. If you're lucky enough to be going to ETech next month, definitely check out Marc's session on Super Ninja Privacy Techniques for Web App Developers.
I hope you found this helpful. Let me know what you think; I appreciate any and all feedback. And if you've got any cool privacy techniques up your sleeve, share the knowledge!
<p>[1] A cryptographic hash is way of mapping any amount of plain text to a fixed-length “fingerprint” such that the same text always maps to the same hash, and given a hash, it is impossible to generate the text from which it was derived. Hashes are wonderful things with many uses. If you’re a developer, and you didn’t already know this, stop reading now and go here or here, and learn how to generate a SHA1/2 hash in your programming language of choice. Come back when you’re ready. I’ll wait.</p>
<p>[2] You can throw in a salt too, to be safe; just make sure that you’re not using the same hash that you’re using for checking the user’s password. You are smart enough not to store passwords in plaintext in the database, aren’t you?</p>