I’m building an iOS app that will make it easy to post to any GitHub-based blog (like this one) from iOS/iPadOS. I’ve finally got the basic pieces together to do an actual post from my phone, and this is it!
My next step is to set up a Sharing Extension so you can write your post in any app (like Apple Notes) and just share to post.
Right now the app just supports Jekyll, but it should be easy to adapt to support any GitHub-based workflow.
Macos Sonoma brought to the Mac the amazing aerial screensavers/wallpapers that can be found on the AppleTV. (I say screensavers/wallpapers because you can choose to have your wallpaper be a frame of whatever your screeensaver is.)
One thing missing, though, are the descriptions of what is being displayed. If I see some amazing place my first question is “where is that?” On the AppleTV you can view the description by clicking (swiping?) up on the remote. There doesn’t seem to be any secret keys or incantations to get it to display on the Mac, though, even though that information is available. If you go into Settings -> Screen Saver on your Mac, you’ll see descriptions:
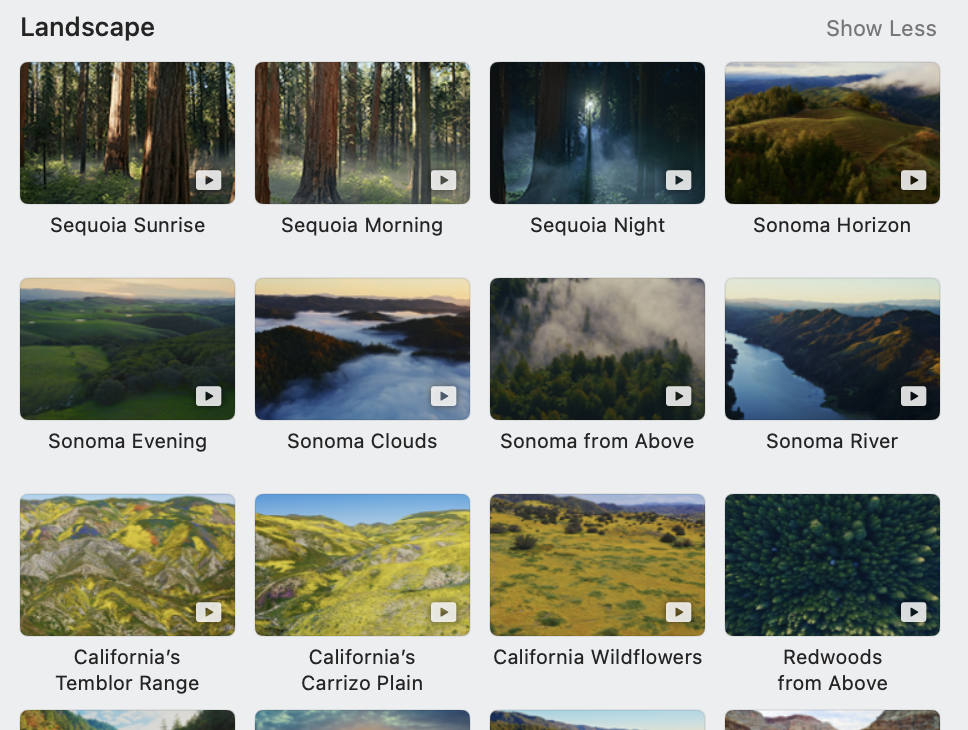
I figured it couldn’t be that hard to (a) find out what the current screensaver is, (b) look up the description somewhere, and (c) find easy way to show that information. It turned out to be not easy, but I did figure it out.
The Screensavers
Searching for “macos where are aerial screensavers stored” gives /Library/Application Support/com.apple.idleassetsd/Customer/4KSDR240FPS. If you open that directory in Finder (run open /Library/Application\ Support/com.apple.idleassetsd/Customer/4KSDR240FPS from the Terminal), you’ll see they’re all MOV videos. Apparently idleassetsd is the process that handles the downloading and display of the aerial screensavers.
My first thought was that maybe the descriptions were encoded in the video somehow, but after digging around in them a bit, that turned out not to be the case.
The Screensaver Database
I looked in the /Library/Application\ Support/com.apple.idleassetsd/ directory and lo! there was sqlite database: Aerial.sqlite:
sqlite> .tables
ZASSET ZUSER Z_1SUBCATEGORIES Z_METADATA
ZCATEGORY Z_1CATEGORIES Z_2ACTIVEFORUSERS Z_MODELCACHE
ZSUBCATEGORY Z_1PINNEDFORUSERS Z_3ACTIVEFORUSERS Z_PRIMARYKEY
Exploring these tables, we find some information, but nothing terribly descriptive:
sqlite> select ZACCESSIBILITYLABEL from ZASSET limit 3;
Iran and Afghanistan
Caribbean
Africa and the Middle East
Ripgrep to the Rescue
Since I knew the description strings had to be somewhere on my hard drive, the next obvious move was to just search for them. I picked a word from one of the descriptions that was unlikely to be found elsewhere—”Temblor,” from “California’s Temblor Range”—and fired up ripgrep.
> rg Temblor /Library/Application\ Support/com.apple.idleassetsd/
>
Nothing. Hmm. After a bit of head-scratching and poking around in other places, I realized that ripgrep by default doesn’t search binary files. So:
> rg --binary Temblor /Library/Application\ Support/com.apple.idleassetsd/
/Library/Application Support/com.apple.idleassetsd/Customer/TVIdleScreenStrings.bundle/sv.lproj/Localizable.nocache.strings: binary file matches (found "\0" byte around offset 12)
/Library/Application Support/com.apple.idleassetsd/Customer/TVIdleScreenStrings.bundle/es_419.lproj/Localizable.nocache.strings: binary file matches (found "\0" byte around offset 12)
...
Bingo! A strings bundle is a collection of localized strings. Given a key that uniquely identifies a string and a language, you can look up the translation of that string in that language.
The next piece was to find all the string keys. The above ZASSET table has a ZLOCALIZEDNAMEKEY column. But, while poking around in the com.apple.idleassetsd folder, I found an entries.json file that had everything I needed in one file:
> cat "/Library/Application Support/com.apple.idleassetsd/Customer/entries.json" | jq ".assets[0]"
{
"id": "009BA758-7060-4479-8EE8-FB9B40C8FB97",
"showInTopLevel": true,
"shotID": "GMT026_363A_103NC_E1027_KOREA_JAPAN_NIGHT",
"localizedNameKey": "GMT026_363A_103NC_E1027_KOREA_JAPAN_NIGHT_NAME",
"accessibilityLabel": "Korea and Japan Night",
"pointsOfInterest": {
"60": "GMT026_363A_103NC_E1027_60",
"150": "GMT026_363A_103NC_E1027_150",
"0": "GMT026_363A_103NC_E1027_0",
"32": "GMT026_363A_103NC_E1027_32",
"195": "GMT026_363A_103NC_E1027_195",
"22": "GMT026_363A_103NC_E1027_22",
"110": "GMT026_363A_103NC_E1027_110",
"260": "GMT026_363A_103NC_E1027_260",
"180": "GMT026_363A_103NC_E1027_180"
},
"previewImage": "https://sylvan.apple.com/itunes-assets/Aerials126/v4/51/ff/08/51ff0824-8da5-78f0-e218-9e61264965bb/[email protected]",
"includeInShuffle": true,
"url-4K-SDR-240FPS": "https://sylvan.apple.com/itunes-assets/Aerials116/v4/cb/5b/50/cb5b5035-6701-619f-9065-3d7d0e5fbef4/comp_GMT026_363A_103NC_E1027_KOREA_JAPAN_NIGHT_v18_SDR_PS_20180907_240fps_0d0095d4-5875-4d43-a1a8-7dc915b11b9dq24_sRGB_tsa.mov",
"subcategories": [
"61171241-39F3-4ADE-84AA-9CD4EE4A78DA"
],
"preferredOrder": 9,
"categories": [
"55B7C95D-CEAF-4FD8-ADEF-F5BC657D8F6D"
]
}
It looks like you can even get different descriptions based on how far along you are in the screensaver video.
The Final Boss: Getting the Active Screensaver
The last bit of information I needed was determining the active (or last active) screensaver. I think I spent the most time on this. I was not able to find anything. Eventually I realized that some process had to have that file open, and if so, lsof would find it.
idleassetsd came up empty, so I looked through my process list for other suspects, and found WallpaperVideoExtension:
> lsof -Fn -p $(pgrep WallpaperVideoExtension) | grep ".mov"
n/Library/Application Support/com.apple.idleassetsd/Customer/4KSDR240FPS/B8F204CE-6024-49AB-85F9-7CA2F6DCD226.mov
Boom!
Putting it all Together
I threw together a little Mac menu bar app, WallpaperInfo. Most of the logic is in Wallpaper.swift:
- Decode all the assets in entries.json.
- Have a description field on the asset that looks up its localized description string in the strings bundle.
- Use
pgrep and lsof to find the aerial video currently active, and use the identifier embedded in the filename to look up the asset.
The result:
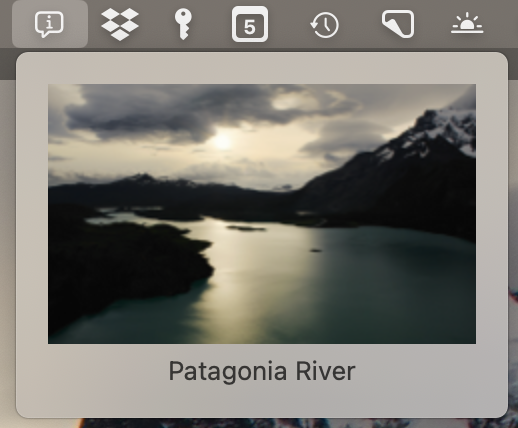
Sadly, I wouldn’t be able to put this in the App Store because of Apple’s sandboxing rules, but feel free to download the binary from my repo.
It would be nice to have the description on the screensaver itself, like the AppleTV does, but I don’t think that’s possible short of either editing the videos to add descriptions, or running your own version of the screensaver. But given that Apple could easily add this as a feature (please!), I didn’t want to invest too much more time into this. I considered my itch scratched.
Or, On Becoming a Cloudflare Fanboy.
What’s wrong with GitHub Pages?
I’d been using GitHub Pages for hosting static sites, including this one, for years. It’s easy and free-ish (I believe they’re free for public repos, and if you’re paying $4/mo, private repos as well).
One thing you don’t get, though, is any kind of visitor metrics. I know I can get this if I add something like Google Analytics to my sites, but I’m loath to do that for a number of reasons. For one, to be GDPR compliant, I’d have to add one of those annoying cookie banners to all my sites. Also, ad blockers can block the GA Javascript and skew results. Finally, I don’t want to have to add the GA code to every site.
If I were hosting the sites myself, I could get the information I need from the web server logs, but if GitHub is hosting the content, they have that info—but they aren’t sharing it.
Enter Cloudflare Pages
I’d been using Cloudflare for a while, as early on it was the only way to enable SSL on your GitHub Pages sites (GH now provides SSL for all Pages). But I didn’t know they had their own “Pages” offering.
Turns out it’s super easy to use: just point it to your GitHub repo, tell it what branch you want to deploy from and if there’s any build commands you want to run (plus other optional settings like output directory, environment variables,etc.), and it will publish your site on a pages.dev subdomain. Then you can add your own domain name via a CNAME record to that subdomain. If Cloudflare is hosting your DNS it will even update your records for you. And everything gets SSL.
(Another advantage of Cloudflare’s Pages offering is I can easily set up a dev/staging site by just creating another Pages site and pointing it to a branch in my repo.)
The analytics it gives you is decent: total requests, unique visitors, bandwidth, % cached, requests by country/region, etc. You can even see breakdown by source IP, browsers, OS, desktop vs mobile (although oddly it’s under the Security section, not Analytics).
One thing that seems to be missing is a breakdown of traffic by page. It would be nice to see, for example, if particular blog posts are getting more traffic than others, but I’m not seeing that data anywhere. Update: They do have this, in a separate section (they really need a good UX person to clean up their menus), and it has to be enabled per site. If you are using their DNS proxy, it will automatically inject their Javascript into your site. Otherwise you can manually insert their JS snippet. They don’t use cookies, and it doesn’t look like they are exposing IP addresses anywhere, so no GDPR concerns.
Going All-In
After moving a few of my sites over and being generally impressed with the Cloudflare experience, I decided to go all-in and consolidate all my domains (more than 20…yes, I have a domain problem) under Cloudflare. This meant having them be my registrar, DNS, and, where appropriate, hosting the content. Previously my domains were spread out among a few different registrars, and my DNS split between registrars, Digital Ocean, and Cloudflare. Having everything under one roof made a lot of sense.
The process was pretty straightforward. The only real snag I hit is that by default Cloudflare sets up “Flexible” SSL/TLS, where traffic is encrypted between visitors and Cloudflare, and then connections to your backend are made over HTTP. But if you already have a cert on your backend, and that backend is configured to redirect HTTP traffic to HTTPS, you’ll end up with a redirect loop. The fix is to just go into Cloudflare and change the SSL/TLS mode to “Full”.
So What Does This Cost?
Nothing. It’s all free…which has been bugging me a bit. Other than registrar fees when transferring domains to them, I haven’t paid them anything. They do have paid plans, of course, but the additional features offered—mostly around security—are targeted towards much bigger sites (bot detection, image optimization, cache analytics, web application firewall, etc.). I would actually be happy to pay them something, but I haven’t hit anything yet to warrant it. However, it seems like the paid plans are all per domain, so if I did end up needing to pay for something across all my sites, it would get unreasonably expensive (their cheapest paid plan, “Pro,” is $20/mo/domain).
Fingers Crossed
I do feel a little nervous about going all-in on Cloudflare, as I would going all-in with any company/service, but I’ve been really impressed with them so far. They’ve had some controversies in the past, but generally seem like a pretty good company, both technically and ethically. I’ll certainly keep you posted if anything changes.
It’s been a bit over a year since I was laid off from Etsy, where I’d been for 11½ years. Although everyone will tell you not to take a layoff personally, it still stings knowing that someone decided you were not worth keeping around. That said, the layoffs seemed to hit old-timers and remotes particularly hard, so the deck was stacked against me.
It wasn’t hard for me to decide not to go looking for another full-time job. I’d long fantasized about being an indie software developer, working on my own things and setting my own schedule, so I guess that’s what I was now.
I started an LLC for all the amazing apps I was going to start writing, but then some consulting fell into my lap. (Coincidentally, this same thing happened to me the last time I was laid off, nearly 25 years ago. I had been working in San Francisco during the dot-com boom and when the company went under I was all set to move to Bishop and become a climbing bum for a year, when a friend pinged me and I ended up spending the next four years consulting.)
I spent a couple months with Wikimedia Foundation creating data modeling guidelines. I learned that WMF has some really interesting and unique challenges, both technically and politically. It’s a really great group of folks.
That was followed a by a much bigger consulting opportunity, which lead to starting another LLC with some friends. We spend about six months tackling a pretty hairy data engineering challenge. What I learned from that is if you see NetSuite, run.
Around the paid gigs I also spent some time helping out one friend with their startup, another with his app, and wrote a web app to help another friend give away free bikes to kids.
I’ve been keeping myself pretty busy since that last gig ended. I spent a good amount of time doing a deep dive into MacOS aerial screensavers/wallpapers. I wrote a Safari extension to redact news articles. I wrote a little web game. I also spent a good amount of December doing Advent of Code, working on my Swift and SwiftUI skills in the process.
I’ll write separate posts about all of those projects, but I’m currently mulling over what to do next. I recently got a 3D printer, so playing with that and learning a bit of CAD has been taking a lot of my time, but that’s not nearly as fulfilling as a good project is.
So after a year of being “indie,” I’m still pretty sure I’m never going back to a full-time jobby-job. I do miss my colleagues at Etsy, and there’s something to be said about being part of a team and a larger mission, but I do not miss all the overhead that comes with working at a “large” company (“work about work”). I love waking up every day knowing that I have zero meetings and what I want to accomplish that day is entirely up to me. Literally whatever.
Now to just come up with that killer app idea….
My friends Sunah Suh, Anthony Hersey, and I finally figured out the magic incantations needed to automate sending “STOP” to political text messages. Setting it up is completely non-obvious, so I’ll walk through it step-by-step.
Note that this is for iOS only. If someone with an Android phone wants to write up their process, I’d be happy to link to it.
Also, this was done on iOS 17.4. Surely this process will change some day. If you notice something is off, let me know and I’ll update it.
 First, open the Shortcuts app and tap the Automation tab at the bottom.
First, open the Shortcuts app and tap the Automation tab at the bottom.
 Tap the plus (+) in the top right corner.
Tap the plus (+) in the top right corner.
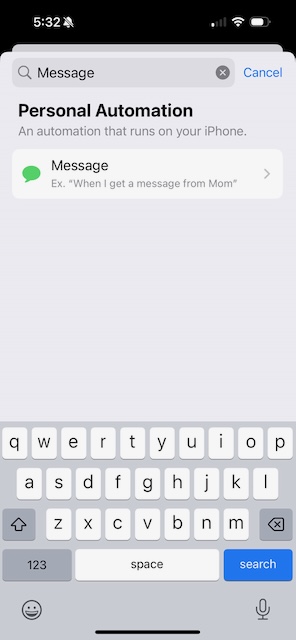 Start typing "Message" in the search bar, and select Message.
Start typing "Message" in the search bar, and select Message.
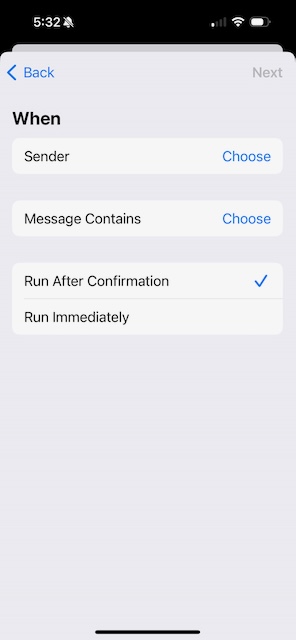 On the When page, hit Choose next to Message Contains.
On the When page, hit Choose next to Message Contains.
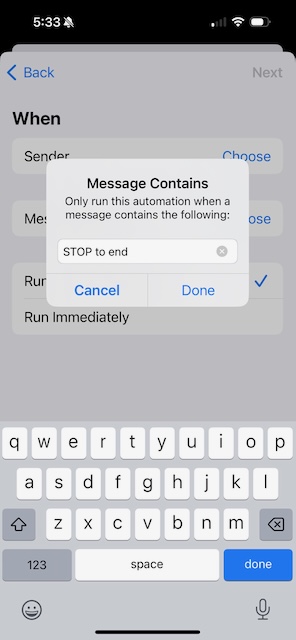 Type in the text to look for, such as "STOP to end". It appears to be case-insensitive.
Type in the text to look for, such as "STOP to end". It appears to be case-insensitive.
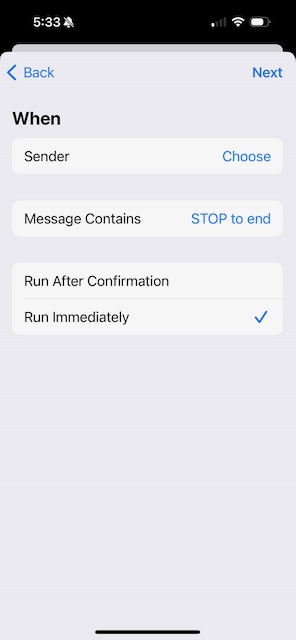 Hit Done and back on the When page, select Run Immediately. Then tap Next in the top-right corner.
Hit Done and back on the When page, select Run Immediately. Then tap Next in the top-right corner.
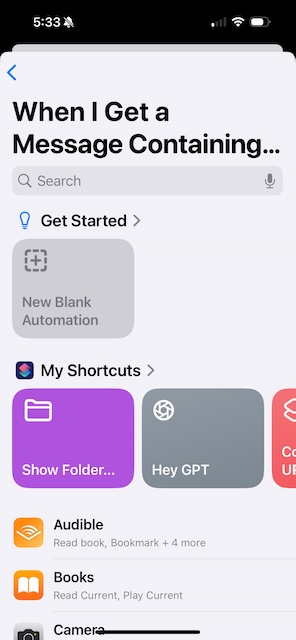 Now select New Blank Automation.
Now select New Blank Automation.
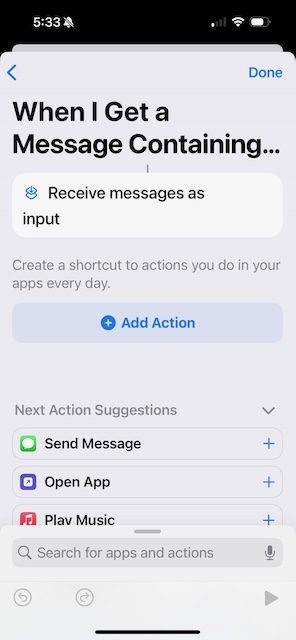 Under Next Action Suggestions, you should see Send Message. (If not, hit Add Action and search for "Send Message".) Tap Send Message.
Under Next Action Suggestions, you should see Send Message. (If not, hit Add Action and search for "Send Message".) Tap Send Message.
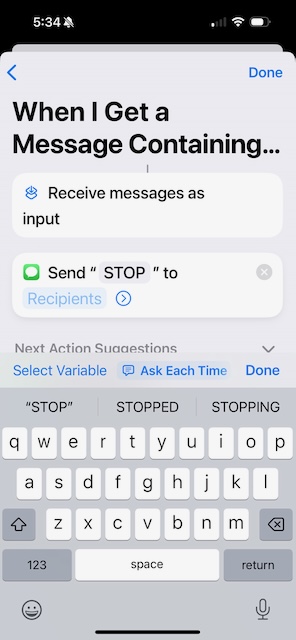 Tap on the Message field and type "STOP".
Tap on the Message field and type "STOP".
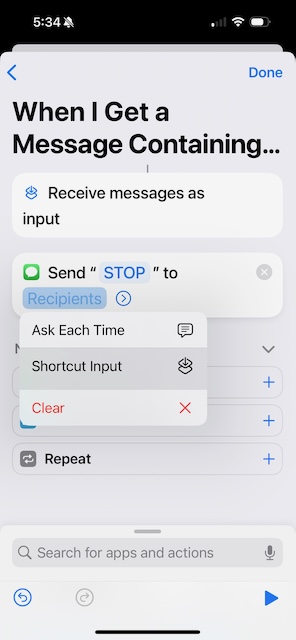 Now comes the first tricky part. Hold down (long press) on Recipients and select Shortcut Input. (If instead it pops open a "To:" page, you didn't hold down long enough. Cancel and try again.)
Now comes the first tricky part. Hold down (long press) on Recipients and select Shortcut Input. (If instead it pops open a "To:" page, you didn't hold down long enough. Cancel and try again.)
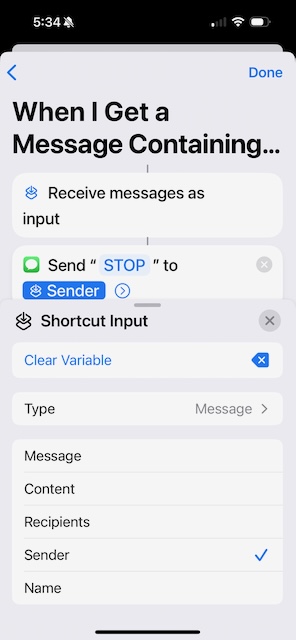 Now the next tricky bit. Tap the Shortcut Input field and select Sender, then hit Done.
Now the next tricky bit. Tap the Shortcut Input field and select Sender, then hit Done.
That's it! Now repeat this for different variations of "STOP to...." ("STOP to quit", "STOP2END", etc.)
