My friends Sunah Suh, Anthony Hersey, and I finally figured out the magic incantations needed to automate sending “STOP” to political text messages. Setting it up is completely non-obvious, so I’ll walk through it step-by-step.
Note that this is for iOS only. If someone with an Android phone wants to write up their process, I’d be happy to link to it.
Also, this was done on iOS 17.4. Surely this process will change some day. If you notice something is off, let me know and I’ll update it.
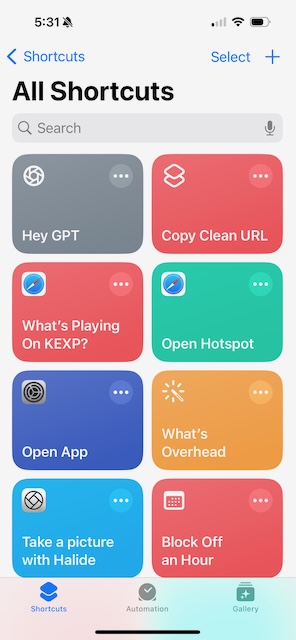 First, open the Shortcuts app and tap the Automation tab at the bottom.
First, open the Shortcuts app and tap the Automation tab at the bottom.
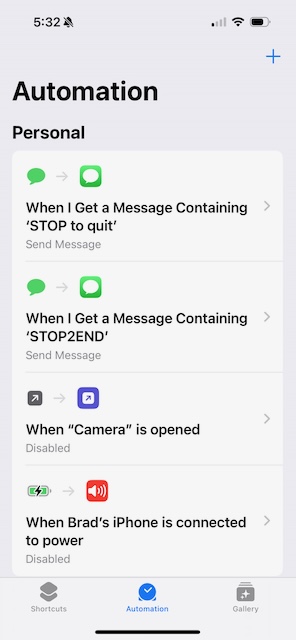 Tap the plus (+) in the top right corner.
Tap the plus (+) in the top right corner.
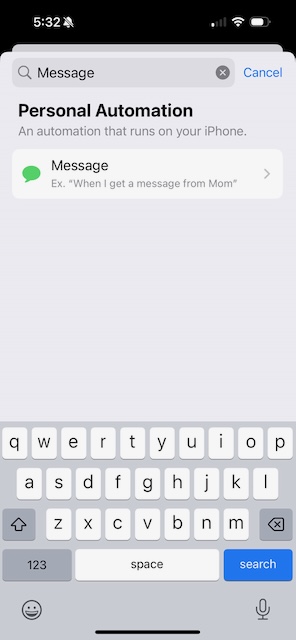 Start typing "Message" in the search bar, and select Message.
Start typing "Message" in the search bar, and select Message.
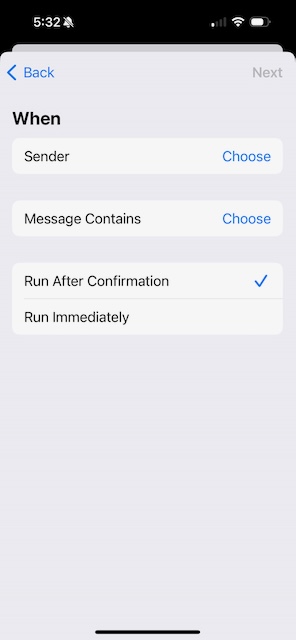 On the When page, hit Choose next to Message Contains.
On the When page, hit Choose next to Message Contains.
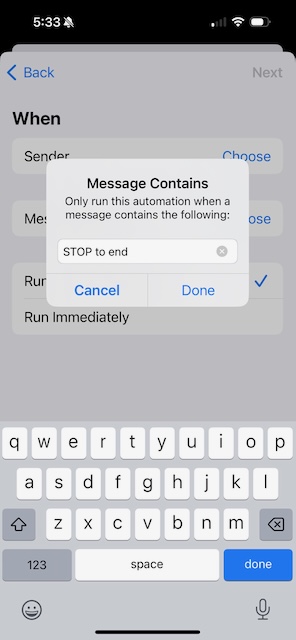 Type in the text to look for, such as "STOP to end". It appears to be case-insensitive.
Type in the text to look for, such as "STOP to end". It appears to be case-insensitive.
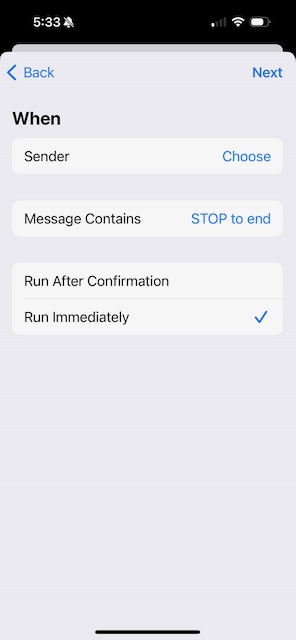 Hit Done and back on the When page, select Run Immediately. Then tap Next in the top-right corner.
Hit Done and back on the When page, select Run Immediately. Then tap Next in the top-right corner.
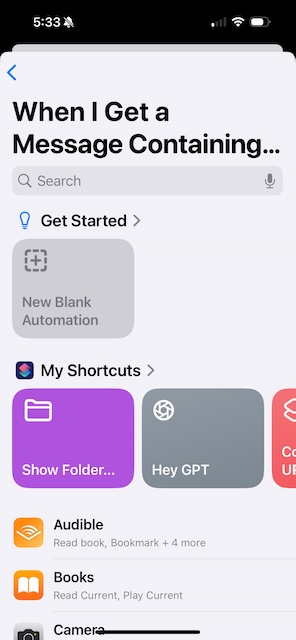 Now select New Blank Automation.
Now select New Blank Automation.
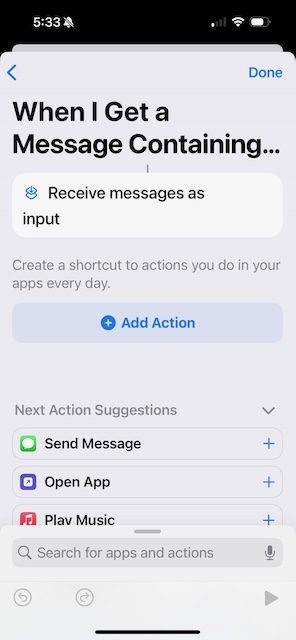 Under Next Action Suggestions, you should see Send Message. (If not, hit Add Action and search for "Send Message".) Tap Send Message.
Under Next Action Suggestions, you should see Send Message. (If not, hit Add Action and search for "Send Message".) Tap Send Message.
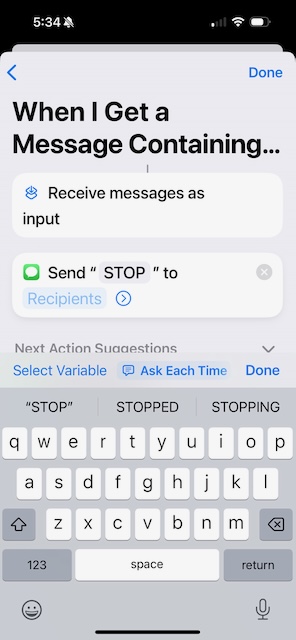 Tap on the Message field and type "STOP".
Tap on the Message field and type "STOP".
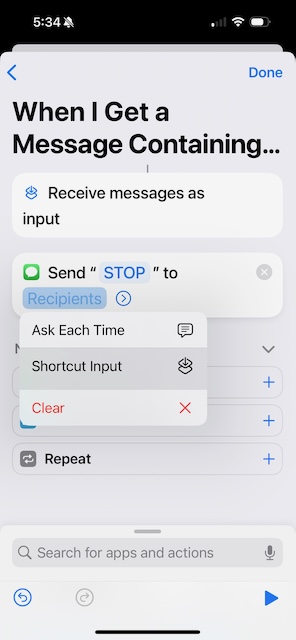 Now comes the first tricky part. Hold down (long press) on Recipients and select Shortcut Input. (If instead it pops open a "To:" page, you didn't hold down long enough. Cancel and try again.)
Now comes the first tricky part. Hold down (long press) on Recipients and select Shortcut Input. (If instead it pops open a "To:" page, you didn't hold down long enough. Cancel and try again.)
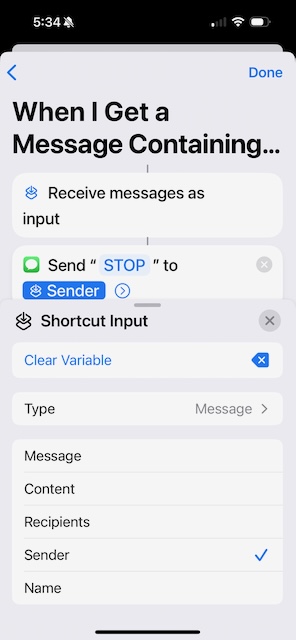 Now the next tricky bit. Tap the Shortcut Input field and select Sender, then hit Done.
Now the next tricky bit. Tap the Shortcut Input field and select Sender, then hit Done.
That's it! Now repeat this for different variations of "STOP to...." ("STOP to quit", "STOP2END", etc.)
One of the engineers on my team at Etsy, who is working on getting our clickstream events into protobuf, noticed that we were getting some values that were too large for protobuf’s largest integer, uint64. E.g: 55340232221128660000.
This value was coming from our frontend performance metrics-logging code, and is supposed to represent the sum of the encodedBodySizes of all the JavaScript or CSS assets on the page. But given that 55340232221128660000 is around 50,000 petabytes, it’s probably not right. There had to be a bug somewhere.
We were only seeing this on a small percentage of visitors to the site—less than 0.1%. I looked at the web browsers logging these huge values and couldn’t see any obvious pattern.
My first thought was that we had code somewhere that was concatenating numbers as strings. In JavaScript, if you start with a string and add numbers to it, you get concatenated numbers. E.g.:
> "" + 123 + 456
< '123456'
But I didn’t see anyway that could happen in our code.
Looking at the different values we were getting, I saw a lot of similar-but-not-quite equal values. For example:
18446744073709552000
18446744073709556000
18446744073709654000
36893488147419220000
36893488147419310000
55340232221128660000
55340232221128750000
55340232221128770000
73786976294838210000
92233720368547760000
The fact that they all end in zeros was curious, but I realized that was because they were overflowing JavaScript’s max safe integer.
I started googling some of the numbers and got a hit. I thought it was very odd that one of our seemingly random numbers was showing up on a StackOverflow post. Then I googled “18446744073709551616”. Any guesses what that is?
264
36893488147419220000? Approximately 2 * 264
55340232221128660000 =~ 3 * 264
etc.
I realized what was probably happening was when we were adding up all the resources on the page, some of them were returning 264-1 (the maximum 64-bit unsigned integer), but some were normal, so that explained the variation.
Now encodedBodySize is an unsigned long long, so my first thought was there is a browser bug that was casting a -1 into the unsigned long long, which would give us 264-1.
I started digging through browser source code. I found that in WebKit, the default value for responseBodyBytesReceived is 264-1, although that value should be caught and 0 returned instead.
Then I went spelunking in the Chromium source, and found this commit, from less than two weeks ago. (Although the bug was reported back in May 2022.) Sure enough, it was a default value of -1 getting cast to an unsigned value. Boom! Mystery solved.
I pushed a fix to our JavaScript to catch these bogus values and hopefully our protos will live happily ever after. Gone are my dreams of finding and fixing a major browser bug, but I’m happy that I can move on with my life.
The Framework for ML Governance by Kyle Gallatin
ML is becoming commoditized, but there hasn’t been much in the way of scalable frameworks to support the delivery and operation of models in production (of course, Algorithmia has one, hence their sponsoring of this report).
ML needs to follow the same governance standards for software & data as other more traditional software engineering does in your organization. In the development phase, this includes validation and reproducibility of your model, and documentation of your methods and rationale. The delivery and operational phases are much more complex, including things like observability, auditing, cost visibility, versioning, alerting, model cataloging, security, compliance, and much more.
MLOps is the set of best practices and tools that allow you to deliver ML at scale. ML governance is how you manage those practices and tools, democratizing ML across your organization through nonfunctional requirements like observability, auditability, and security. As ML companies mature, neither of these are “features” or “nice-to-haves”—they are hard requirements that are critical to an ML strategy.
Data scientists can’t do this all by themselves. They need support from the larger organization. The value of ML governance needs to be understood at the highest levels. They should involve infrastructure, security, and other domain experts early on, and be sure to be open in their communication with the rest of the company.
Advent of Code was a fun diversion this year. It seemed a bit easier than some previous years. Perhaps it helped that I picked a language that I had some experience with, Swift. Here are some quick thoughts on Swift as an AoC language, some general AoC tips, and notes on some of the more interesting puzzles.
You can find all my 2020 code here.
Swift for AoC
First, the complaints:
Swift is too pedantic about strings. AoC usually involves loads of string manipulation and parsing, so being able to easily index into strings is super helpful. Swift does not make this easy out-of-the-box. I understand why. Strings are complicated in a language like Swift that supports Unicode well. Indexing into an array is expected to be a constant-time operation, but that’s not possible when you have to look at the preceding bytes in order to figure out what the _i_th character is. Still. You can at least make it easier and less ugly than myString[myString.index(myString.startIndex, offsetBy: i)]. Thankfully Swift is easy to monkey-patch, so I added some useful extensions to make it tolerable.
Regexes are similarly annoying in Swift. Here it just feels like they never properly ported them over from Objective-C. Here’s an example:
// print the animals found in a string
let myString = "The quick brown fox jumped over the lazy dogs."
let animalsRegex = try NSRegularExpression(pattern: #"(fox|dog)"#, options: [])
let matches = animalsRegex.matches(in: myString, options: [], range: NSRange(myString.startIndex..<myString.endIndex, in: myString))
for match in matches {
for i in 1..<match.numberOfRanges {
print(NSString(string: myString).substring(with: match.range(at: i)))
}
}
My colleague Mike Simons gave me a RegEx helper he uses, which reduces the above to:
let animalsRegex = try RegEx(pattern: #"(fox|dog)"#)
let matches = animalsRegex.matchGroups(in: myString)
for match in matches {
for group in match {
print(group)
}
}
Tuples not being hashable or even extendable is a pain for a lot of AoC problems. I resorted to using a custom struct for a bunch of problems, but at some point discovered SIMD vectors, which have the added benefit of having arithmetic operators defined for them.
What I loved about Swift:
Working with a statically-typed language in a proper IDE (Xcode) is such a huge time-saver. Everything is checked as you type (which can be a little annoying when Xcode starts scolding you for not using variables that you’ve defined before you get a chance to write the code that uses them; but you learn to ignore it). You have a full-featured debugger.
Playgrounds are really useful for trying out quick snippets of code.
Swift is generally a pleasant, straight-forward language to write. There’s not all the overhead of thinking about memory and ownership like there is in Rust, for example.
It’s actually pretty performant—at least when not running the debug build (I usually got a 10x speed-up when building for release).
General AoC Tips
- Hash maps, hash maps, hash maps. Even if the problem seems array-shaped, there’s a good chance a hash map will be more efficient.
- Many of the problems are grounded in some basic CS principle (day 5 this year being a classic example). Think about what that might be before diving in.
- Oftentimes part 2 will be part 1 but MORE. Days 15 (Rambunctious Recitation) and 23 (Crab Cups) this year were good examples of that. When coding part 1, think about how your solution might scale if you were doing a million times more, or with a million times more data.
The Puzzles
Ok, on to specific puzzles. I’m just going to talk about some of the more interesting ones. Spoilers follow:
This is a classic AoC problem in that it disguises basic CS principles. If you were to solve this naively, it might be kind of annoying. but when you realize that the seating strings (e.g. FBFBBFFRLR) are just binary numbers, with (F,L) -> 0 and (B,R) -> 1, it becomes trivial. Particularly helpful here was Swift’s ability to convert a binary string to decimal with Int(binary, radix: 2).
Part 1 just required sorting the list of converted seat numbers and taking the last (highest) one. Part 2, finding the first non-consecutive id, is probably faster just iterating through the sorted list and stopping on the first id that is not one more than the last id (which is what I did originally), but it was more fun and concise to use Gauss’ formula to calculate what the total should be if all the consecutive numbers were present and subtract the actual sum of all numbers.
For kicks, I did a “no code” version in a spreadsheet.
This was the first day that required some real thought. I started down the path of having a bidirectional graph with each bag having parents and children, but I got bogged down. I think sometimes creating objects complicates things vs. just slinging around string hash maps.
This is totally an interview question I would have failed. It’s easy enough doing it the “dumb” (O(n^2)) way that I did it, constructing a lookup table of all sums in the preamble, or, for part 2, iterating through every possible sequence of two consecutive numbers, then three, etc.—also O(n^2). After I finished, a friend shared the “inchworm” technique, which is O(n). Neat! I totally failed that interview.
Part 2 was fun to figure out. There were very different ways to approach this. I went with recognizing that we were dealing with power sets. I wrote up my thinking in my code, so I won’t duplicate it here. Some friends solved this using dynamic programming, which I definitely need to level up on.
Nothing particularly interesting here—the first of three Game of Life-type problems. I just had to share this, though.
Pretty straightforward. Part 2 was fun because I [re-]learned how to rotate a vector.
This was a fun one. I solved part 1 in bed on my phone with a calculator, and then spent the entire next day working on part 2. I learned about the Extended Euclidean algorithm and the Chinese remainder theorem. I used the existence construction to solve it, but the simpler solution that many used was sieving.
Game of Life again! Doing it in 3D and then 4D was a fun twist. Nothing particularly tricky. I just have a soft spot for GoL.
This was a fun one. I spent a lot of time scratching my head and drawing diagrams, until I remembered it’s a lot easier to parse expressions in postfix, and you can use the Shunting yard algorithm to convert infix to postfix.
Woo, boy! This was a good one. I’d never written a parser before, so this was a learning experience. My part 1 solution involved creating a matcher from the grammar, and it was fast and elegant. Part 2 threw in the wrench of recursive rules, which absolutely do not work when building a matcher. I tried a whole bunch of things like adding recursion limits, but I could not get it to work. I ended up moving on and came back to it only after I’d finished all the other days. By then I had heard the term CYK algorithm bandied about, and so I did a complete rewrite using that. I spent a bunch of time reading about the algorithm and about Chomsky normal form. I “cheated” a bit and didn’t write code to convert the provided rules to Chomsky normal form, as there were only a few rules that needed to be tweaked and it was easy enough to do it by hand:
| Original |
Chomsky normal form |
107: 18 | 47 |
107: "b" | "a" |
11: 42 31 | 42 11 31 |
11: 42 31 | 42 133
133: 11 31 |
8: 42 | 42 8 |
8: 47 50 | 18 4 | 42 8 |
This was a favorite. Part 1 was easy once I figured out a way to generate a hash code that uniquely identified a side, irrespective of its orientation:
static func sideToInt(_ side:String) -> Int {
let binary = side.replacingOccurrences(of: ".", with: "0")
.replacingOccurrences(of: "#", with: "1")
let num = Int(binary, radix: 2)!
let numReversed = Int(String(binary.reversed()), radix: 2)!
return num * numReversed * (num ^ numReversed)
}
Once you have that, your corners are the tiles that have two “singleton” sides (i.e. unique to that tile). No assembling necessary…for part 1. Part 2 did require assembling, and that was a bit tedious. It was a cool problem, though.
Classic AoC problem where the simple solution for part 1 utterly fails in part 2. I actually got the answer to part 2 after letting my dumb-but-optimized part 1 solution run overnight, but while it was running, mulling it over in bed, I realized that this was a linked list problem. I fixed it in the morning and the runtime went from ~ 7 hours to 0.2 sec.
This was surprisingly easy for this late in the calendar, although my first naive attempt trying to map it to a 2D coordinate system failed. But I googled “hexagonal grid coordinate system” and found this cool page. I used the cube coordinate system and it was easy-peasy.
Part 2: Yay, more Game of Life! I’m sorely tempted to write a visualization for this.
I scratched an itch last week and actually wrote some code (these days my primary IDE is Google Docs). Check out humanize, which replaces any large numbers in text piped into it with shortened versions using SI prefix symbols (K, M, G, T, etc.). So “File size: 972917401236” becomes “File size: 973G”.
This came about because I was debugging an issue with a Parquet file using parquet-tools, whose output looks like:
% parquet-tools meta part-01373-r-01373.gz.parquet | grep "row group"
row group 1: RC:100 TS:121513011 OFFSET:4
row group 2: RC:100 TS:44877183 OFFSET:14293218
row group 3: RC:111 TS:28645460 OFFSET:19704281
row group 4: RC:168 TS:31794536 OFFSET:23387243
row group 5: RC:363 TS:28078938 OFFSET:27531686
row group 6: RC:15547 TS:899825873 OFFSET:31242035
row group 7: RC:9963 TS:47930700 OFFSET:142353955
row group 8: RC:20100 TS:911417774 OFFSET:155302131
row group 9: RC:20100 TS:889810662 OFFSET:269749697
row group 10: RC:10100 TS:855908709 OFFSET:382090935
row group 11: RC:7282 TS:1532744480 OFFSET:486019001
Tired of squinting and counting digits to see how big some of these numbers were, I figured there’d be some easy bash/sed way to convert these numbers into something more readable. It is pretty easy to do this for isolated numbers using numfmt:
% echo "1234567890" | numfmt --to=si --round=nearest
1.2G
But that doesn’t work on numbers embedded in text:
% echo "This is a big number: 1234567890" | numfmt --to=si --round=nearest
numfmt: invalid number: ‘This’
GNU sed can do a replacement with the result of a function, but it’s rather ugly:
% echo "This is a big number: 1234567890" | sed -re 's/[0-9]+/`numfmt --to=si --round=nearest &`/g;s/.*/echo &/;e'
This is a big number: 1.2G
But I’m doing this work on a Mac, which does not come with GNU sed (or numfmt, for that matter, although you can brew install coreutils to get gnumfmt). I started working on a perl one-liner to do it, but decided this was something that needed to exist on its own, and should be easy for anyone to install.
I chose to write it in Go because it has an easy way for people to install binaries with go get. (Rust has something similar with cargo install, but Go is more common in my workplace.) The problem with go get is that you have to run it again to upgrade, so for my fellow Mac users I added a Homebrew tap.
Long story short:
% parquet-tools meta part-01373-r-01373.gz.parquet | grep "row group" | humanize -binary
row group 1: RC:100 TS:116Mi OFFSET:4
row group 2: RC:100 TS:43Mi OFFSET:14Mi
row group 3: RC:111 TS:27Mi OFFSET:19Mi
row group 4: RC:168 TS:30Mi OFFSET:22Mi
row group 5: RC:363 TS:27Mi OFFSET:26Mi
row group 6: RC:15Ki TS:858Mi OFFSET:30Mi
row group 7: RC:10Ki TS:46Mi OFFSET:136Mi
row group 8: RC:20Ki TS:869Mi OFFSET:148Mi
row group 9: RC:20Ki TS:849Mi OFFSET:257Mi
row group 10: RC:10Ki TS:816Mi OFFSET:364Mi
row group 11: RC:7Ki TS:1Gi OFFSET:464Mi